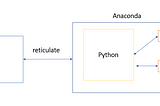
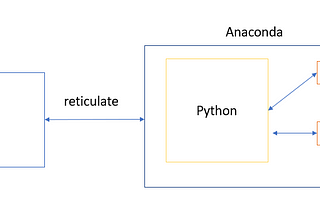
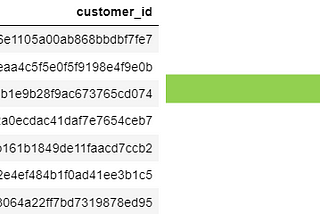
PinnedAnnie WangHow to run Keras and Tensorflow in RstudioCreate Python env for Keras in RstudioDec 12, 2021Dec 12, 2021
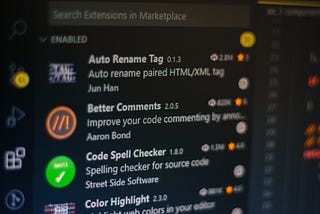
PinnedAnnie WanginTowards Data ScienceWhy Matplotlib can’t be installed in Visual Studio CodeBecause of MVC++ Build toolsNov 25, 20213Nov 25, 20213
PinnedAnnie WanginTowards Data ScienceSplitting the text column and getting unique values in PythonA user case for a none-fixed-length text columnDec 3, 20201Dec 3, 20201
Annie WanginGeek CultureHow to run HTML in Visual Studio CodeThe extensions: HTML Preview, Live Server and open in browserAug 17, 2021Aug 17, 2021
Annie WanginTowards Data ScienceTraversing , cleaning batch worksheets in batch Excel files and interacting with MySQLCleaning only with pandasJun 27, 2021Jun 27, 2021
Annie WangA concise function to transfer text to number in DataFrameToday I want to share a concise function that can transfer text to numbers. Let’s show the original and target data first to get a direct…Jun 26, 2021Jun 26, 2021
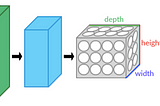
Annie WanginTowards Data ScienceFormulate the shape and number of parameters for a simple CNNMay 19, 2021May 19, 2021
Annie WangUnderstand the basic 6 functions in PyTorchsqueeze(), unsqueeze(), tensor[None],max(),argmax(), and view()May 5, 2021May 5, 2021
Annie WangFunkSVD: math, code, prediction, and validationA brief intro for FunkSVD, prediction, and validation with examplesApr 7, 2021Apr 7, 2021
Annie WanginTowards Data SciencePredict ratings with SVD in collaborative filtering recommendation systemIncludes how to convert SVD to k dimension and making predictionMar 30, 2021Mar 30, 2021